Computational Semantics Hackathon
This year, IWCS will feature a Computational Semantics Hackathon, before the main conference on April 11th-12th from 10:00 to 17:00.
We invite researchers, developers, students and users of semantic NLP tools to participate. The goal of the event is to provide an opportunity to discuss and develop tools that are used in Computational Semantics. Moreover, we also would like to attract anyone interested in data processing tools so they could contribute to open source projects represented at the event. You don't need to attend the conference to be able to participate at the hackathon.
The event will take place at Ground Cafe. It's building 33 on the QMUL campus map. Please refer to the location page for more information on how to get to the QMUL Mile End Campus.
The hackathon is organised by the Computational Linguistics lab at QMUL and sponsored by the EPSRC grant EP/J002607/1 — Foundational Structures for Compositional Meaning and EECS. GitHub kindly offers subscription coupons for the 3 winning teams.
Presented projects
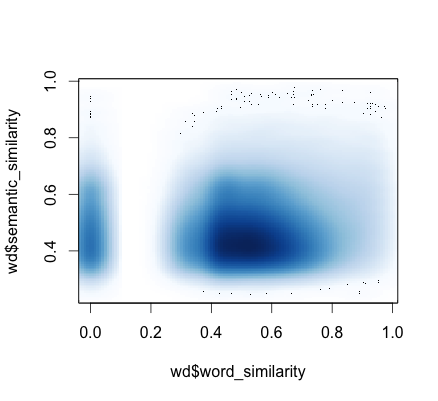
Semantic-sounds
Investigated the extent to which semantically similar words sound similar. Check their article for more details.
Poett
Generated poems and haikus from tweets.
>>> print(analogyFromTweet('what is the meaning of a good life?'))
The life numbers like a percipient
The recipients presss like a recipient
>>> print(analogyFromTweet('what is the meaning of a good life?'))
The life numbers like a percipient
The recipients presss like a recipient
>>> print(analogyFromTweet('the sparrow is chirping on the tall wall'))
The wall gapes like a relic
The walls depends like a angelic
Announcements
Sunday
It's the final day of the hackathon. Coding should stop at about 16:00. Then the teams will present their projects and we vote to for the best project/team/presentation.
Saturday
We are glad to welcome you to the hackathon! Saturday morning, the time before the coffee break, is dedicated to introduction. It's also a great opportunity for you to set up wifi, talk to people and decide on a project.
We will use a Trello board to keep track of the progress. You should have received an invitation email to the board, if not ask someone who is added to it to add you. Each project is assigned a color, so you can see to which project a card belongs. If you are interested in a task, please add yourself to a corresponding card. Feel free to add your own projects in the Comments.
From the software point of view, it's nice to have Python installed on your laptop. We suggest to install Miniconda (there is a USB drive with the installation scripts, just in case) and create a dedicated virtual environment with common packages:
# Create an environment
~/miniconda3/bin/conda create -n iwcs15-hack python=3.4 nltk pandas scikit-learn ipython-notebook
# Activate it
source ~/miniconda3/bin/activate iwcs15-hack
# Install a package using conda (preferred)
conda install flask
# Install a package using pip if conda can't find it
pip install more_itertools
Register on github and bitbucket. Generate SSH keys and the public key to the services. Use the iwcs15-hack organization to store and share code. Share you github account name in the comments, so we could add you to the organization.
Get a good text editor, for example Atom or SublimeText.
Help others or ask for help! Use comments or a dedicated channel for communication. Network. Have fun.
A distributional semantic toolkit (Green)
This project aims to provide researchers working in distributional semantics with a set of core Python utilities. The following functionality is required:
- A space-efficient datastructure for storing distributed representations of words and phrases, e.g. through memory-mapped numpy arrays or bcolz-backed pandas data frames
- Efficient exact and approximate nearest neighbour search, e.g. through a scikit-learn's KD-tree or random projections
- Efficient dimensionality reduction (SVD, NMF) and feature reweighting (PMI, PPMI)
- Converters to and from commonly used formats
- Easy evaluation against a set of word similarity datasets, such as Mitchel and Lapata (2008) or MEN
The project will involve merging and documenting existing pieces of software, such as DISSECT, fowller.corpora and discoutils. Check out a relevant discussion on including word embedding algorithms to NLTK.
Compositionality for distributional semantic toolkits (Yellow)
It has been shown that some type-logical grammars can be interpreted in vector space semantics, so the challenge here would be to build a tool that connects such a grammar to a distributional setting.
Ingredients are a representation of such grammars in terms of a lexicon/derivation rules, a suitable interpretation of types and proofs into tensor spaces and maps, and distributional data.
Given a lexicon and derivational rules, a theorem prover such as z3 provides a proof for a given input sentence which is later used to obtain distributional representation.
LG is a theorem prover by Jeroen Bransen, see his MSc thesis. It's written in C++, takes a .txt file (lexicon) as input and produces a tex/pdf as output.
Wikipedia dump postprocessing (Orange)
Wikipedia provides dumps of all its content. However, to be used by NLP tools (for example parsers) a dump has to be cleaned up from the wiki markup. The postrocessing steps are rarely described in details in scientific literature. A postprocessed Wikipedia dump from 2009 is often used in current literature.
The goal of this task is to come up with a easy to deploy and well documented pipeline of processing a Wikipdedia dump. There are two steps in the pipeline: raw text extraction and parsing.
There are at least two ways of getting raw text out of a Wikipedia dump. Wiki markup can be filtered out using regular expressions, as it's done in gensim and Wikipedia Extractor. Alternatively, text in the wiki markup can be parsed using Parsoid to obtain (X)HTML, later this HTML is processed, for example tables and images are removed (see this notebook). Pandoc and Docverter is a powerful document conversion solution that can be used to convert a wiki dump to plain text.
Later the raw text of a dump can be parsed by some of these parsers:
It might be worth submitting the results to 10th Web as Corpus Workshop (WaC-10).
There is work in progress on making HTML dumps available, see T93396 and T17017.
NLTK corpus readers (Red)
NLTK is a natural language toolkit that provides basic tools to deal with textual information. Corpus readers are interfaces to access textual resources (called corpora). The task is to provide interfaces to the following resources.
- Groningen Meaning Bank: the Groningen Meaning Bank is a free semantically annotated corpus that anyone can edit.
- UkWaC: UkWaC is a 2 billion word corpus constructed from the Web limiting the crawl to the .uk domain.
- AMR: the AMR Bank is a set of English sentences paired with simple, readable semantic representations.
Tweet paraphrase generator (Violet)
Given a tweet, the system has to come up with a paraphrase. For example, by substituting all the content words (nouns, verbs, adjectives and adverbs) with similar words.
A twitter bot should monitor Twitter for tweets that contain #iwcs or #iwcs2015 and generate a paraphrase tweet. Also, tweets directed to the bot should be replied with a paraphrase.
Twitter stream analysis (Blue)
We are collecting tweets about Easter, Cricket World Cup, IWCS, UKG Fest, London, and the London Marathon. In addition we are gathering geo located tweets from the UK. The task is to give insights of what these streams are about. Some limited statistics about the collected tweets:
du -hs * 632M cricket 816M easter 13M ep14 199M heartbleed 56K iwcs 8.1G london 2.1M london-marathon 2.0G uk 1.9M ukg-fest
Poultry is a tweet collection manager that might be handy that provides a simple access to a tweet collection.
Dialog system (Light Blue)
Matthew Stone provided a series of IPython Notebooks (github repo, rendered notebooks) that implement and extend the original Eliza program, and build a dialog move classifier using NLTK and use information retrieval to put together relevant responses.
Other resources
- Distributional vectors for 23586 words extracted from Google Books Ngrams.
- GoogleNews-vectors-negative300.bin.gz word2vec vectors use gensim.models.word2vec to access the word vectors and perform similarity queries.
- SimLex999 is a gold standard resource for the evaluation of models that learn the meaning of words and concepts.
More project ideas
Participants and sponsors are welcome to propose any and all ideas relating to computational semantics - please get in touch, submit a pull request with your idea added to this page, or just write it down in the comments below
Contact information
In case you are interested in supporting the event contact Dmitrijs Milajevs <d.milajevs@qmul.ac.uk>.


